

Vorige week werd een unieke dataset gepubliceerd onder de noemer Wet Open Overheid. In deze downloadbare bestanden zaten meerdere excelsheets met aanvraaggegevens over Subsidie Elektrische Personenauto’s Particulieren (SEPP) van 2020 tot en februari 2023. In deze gegevens was bewust gekozen om kentekens niet mee te sturen. Met slimme data matching is echter groot gedeelte van deze verwijderde kentekens te reconstrueren, blijkt uit onderzoek van Kenteken.TV.
Woo publicatie SEPP aanvragen
Vorige week werd als uitkomst van een Woo verzoek documenten en bestanden van aanvragen Subsidie Elektrische Personenauto’s Particulieren (SEPP) geopenbaard. Deze gegevens zijn afkomstig van Rijkdienst van Ondernemend Nederland (RVO). Woo is de opvolger van Wet openbaarheid van bestuur die ook wel bekend was als WOB. Wet open overheid is hiervan per 1 mei 2022 de vervanger.
Op basis van deze gegevens zijn er allerlei analyses te maken over SEPP subsidieaanvragen. Hierover is een apart bericht op deze blog verschenen.
Kentekens zijn nationale identificatienummers
In de aanvraag werd verzocht om detailgegevens van subsidie aanvragen, waaronder gegevens over voertuigen en aanvragers. In de aanvraag werd ook verzocht om kentekens van de voertuigen waarvoor aanvragen werden gedaan. Vanwege artikel 5.1 van de Woo is echter besloten om dit gegeven niet aan te leveren in de bestanden. De verklaring hiervoor is het volgende:
Nationale identificatienummers (5.1.1.e)
Citaat uit Woo besluit SEPP aanvragen
Op grond van artikel 5.1, eerste lid, aanhef en onder e, van de Woo mag ik geen
informatie openbaar maken als dit een nationaal identificatienummer betreft,
zoals het BSN-nummer of het kenteken van een voertuig. In de documenten 1 tot
en met 4 staan nationale identificatienummers betreffende kentekens. Ik zal deze kentekens daarom niet openbaar maken.
In het bestand Overzicht SEPP aanvragen (2022).xlsx is zodoende conform besluit de kolom kenteken leeggehaald:
Kentekens reconstrueren op basis van andere gegevens
In de aanvraag voor subsidie moet je als aanvrager gegevens over je voertuig aanleveren. Een belangrijk veld is daarbij het kenteken. Op basis van het kenteken worden namelijk bij BasisRegistratie Voertuigen (afgekort BRV, maar ook wel bekend als kentekenregister) aanvullende gegevens opgevraagd. Deze gegevens zijn in beheer bij RDW. In de bestanden zijn de volgende RDW gegevens terug te vinden:
- Merk
- Model (Handelsbenaming in BRV)
- Type
- Catalogusprijs
- Datum eerste toelating
Deze gegevens zijn voor de beoordeling van de subsidie aanvragen belangrijk. Er zijn bijvoorbeeld wettelijke regels ten aanzien van oorspronkelijke nieuwprijs van de auto. Deze dient tussen € 12.000 en € 45.000 te liggen. Ook de datum eerste toelating is belangrijk voor het proces.
Bij het bekijken van de bestanden werd ik nieuwsgierig. De kolom Kenteken was leeg, maar zou het wellicht kunnen om deze kentekens terug te vinden op basis van de andere aangeleverde gegevens? Een datum bestaande uit dag, maand en jaar en een catalogusprijs bestaande uit 5 cijfers zijn bij elkaar namelijk redelijk uniek. Zeker in combinatie met een merk en handelsbenaming.
Deze hypothese heb ik jaren geleden al eens kunnen bewijzen met een dataset met verkeersongevallen in Nederland. In deze dataset ontbraken ook kentekens, maar was door middel van creatieve data matching ook kentekens te reconstrueren. Uiteindelijk is er destijds niets met deze opvallende uitkomsten gebeurd. De bewuste dataset werd overigens vrij snel daarna aangepast waardoor dit niet langer meer kon.
Onderzoeksopzet voor reconstructie kentekens
Om de hypothese te bevestigen dat kentekens te reconstrueren zijn, heb ik een specifieke excelsheet met macro krachten samengesteld waarmee per dataregel 4 queries bij RDW opendata werden afgevuurd:
- Hoeveel matches zijn er te vinden op basis van datum eerste toelating en catalogusprijs?
- Hoeveel matches zijn er te vinden op basis van merk, datum eerste toelating en catalogusprijs?
- Hoeveel matches zijn er te vinden op basis van merk, model, datum eerste toelating en catalogusprijs?
- Indien op vraag 3 slechts één resultaat kwam: wat was het kenteken?
Voordat het proces gestart werd, heb ik 1 groot bestand gemaakt van de subsidie aanvragen uit 2020, 2021, 2022 en 2023. Dit vereiste nog wat data correcties voordat het proces gestart kon worden. In uiteindelijke bestand stonden 58.959 records. Een groot gedeelte van deze records bevatte geen RDW gegevens, namelijk 11.930. Dit zijn waarschijnlijk afgekeurde subsidie aanvragen.
Er waren dus 47.029 records over die minimaal drie keer verrijkt moest worden. Dat proces had dus wat doorlooptijd om te completeren. De output werd per regel weggeschreven in een excelsheet:
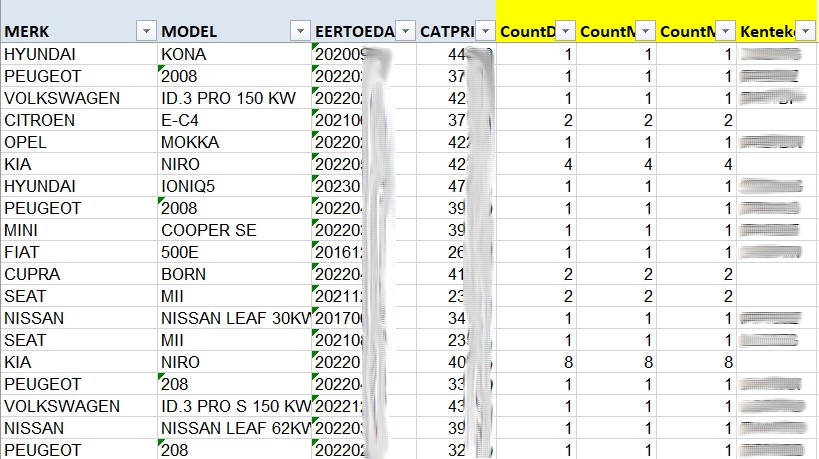
Uiteindelijk werd er bij 25.473 dataregels een kenteken gevonden. Dat is 43,6% van het totale bestand. Bij de andere dataregels werden twee of meer matches gevonden (zoals in screenshot bij KIA NIRO acht matches werden gevonden).
Bij groot gedeelte was voor deze unieke matching enkel datum eerste toelating en catalogusprijs afdoende, maar de matching werkte nog beter met meer gegevens zoals merk en model.
Responsible disclosure
Duidelijk in het voorgaande screenshot is te zien dat kentekens en twee andere kolommen vaag zijn gemaakt. Dat heb ik bewust gedaan. De overheid heeft bij publicatie van deze gegevens ervoor gekozen om geen kentekens te ontsluiten. En dat respecteer ik.
In het screenshot zit ook gelijk mijn advies aan partijen die soortgelijke bestanden willen ontsluiten en vorm van anonimiseren willen toepassen. Door bijvoorbeeld datums en catalogusprijzen af te ronden is het niet langer mogelijk om kentekens met grote zekerheid te reconstrueren. Met enkel merk en model voor een redelijk populaire auto is het kenteken niet langer te achterhalen. Bij exotische merken en modellen blijft dit wel mogelijk op basis van merk en model. Zo staat in de bestanden van RVO een subsidie aanvraag voor een ZOTYE. En daar is voorlopig nog maar één exemplaar van in Nederland.
Aantal voertuigen op postcodeniveau
RDW zelf gebruikt hiervoor een andere methode. Veelvuldig krijgt de dienst vragen over ter beschikking stellen van aantal (elektrische) voertuigen op postcode. In 2019 heeft RDW besloten om via haar opendata platform een deel van deze informatie vrij te geven. Dit is vervolgens niet op kentekenniveau gedaan, maar op een bepaald aggregatieniveau. De redenering hierachter is het volgende:
Aangezien traceerbaarheid van de verblijfslocatie van specifieke voertuigen onwenselijk is, toont het overzicht alleen aantallen van 10 geregistreerde voertuigen en meer. Staan er van een bepaalde onderverdeelde voertuigsoort minder dan 10 exemplaren op een postcode geregistreerd dan is dit aantal niet zichtbaar. Het gevolg hiervan is dat het overzicht geen volledige afspiegeling van het Nederlandse wagenpark is.
RDW over traceerbaarheid van de verblijfslocatie van specifieke voertuigen
Reactie RVO
Voor publicatie van dit artikel heb ik deze week veelvuldig contact gezocht met RVO. Op basis van mijn aangeleverde informatie hebben ze intern veelvuldig besproken of publicatie van de gegevens naar aanleiding van Wet Open Overheid verzoek aangepast moest worden.
Gaandeweg de week hebben ze vanuit verschillende oogpunten naar dit vraagstuk gekeken: vanuit privacy oogpunt, vanuit Woo oogpunt, vanuit verantwoordelijkheden oogpunt. Vragen die hierbij over tafel zijn gegaan, waren o.a.:
- Hoe erg is het als mensen weet hebben dat een specifiek voertuig subsidie heeft ontvangen?
- Zijn we als RVO verantwoordelijk voor dat een groot gedeelte van RDW kentekenregister vrijelijk beschikbaar is? En dat hiermee door koppeling met onze bestanden kenteken achterhaald kunnen worden?
- Hoe is het Woo besluit proces voor dit specifieke besluit verlopen?
De kern van deze vragen draait allemaal om de vraag of een kenteken wel of niet een persoonsgegeven is. Hierover zijn al diverse malen gerechtelijke procedures gevoerd. De kern is hierbij het volgende:
Kentekens kunnen inderdaad persoonsgegevens zijn als ze herleidbaar zijn tot een individu
Persoonlijk denk ik dat in dit specifieke geval wel sprake is van persoonsgegeven. Het is namelijk een individuele beslissing op de voertuigeigenaar aanspraak wil maken op deze specifieke subsidie. Volgens dezelfde redenatie publiceert RDW bijvoorbeeld niet in de openbaarheid of je voertuig geschorst is bij hun. Dat is namelijk een persoonlijke keuze.
Voordat deze discussie echter bij RVO tot afronding is gekomen, hebben ze in ieder geval besloten om de Woo publicatie voorlopig in te trekken. Dat heeft vandaag vrijdag 24 maart plaatsgevonden. In welke vorm deze gegevens terug zullen keren, is op dit moment nog onduidelijk.